rocketsled is a flexible, automatic (open source) adaptive optimization framework “on rails” for high throughput computation. rocketsled is an extension of FireWorks workflow software, written in Python.
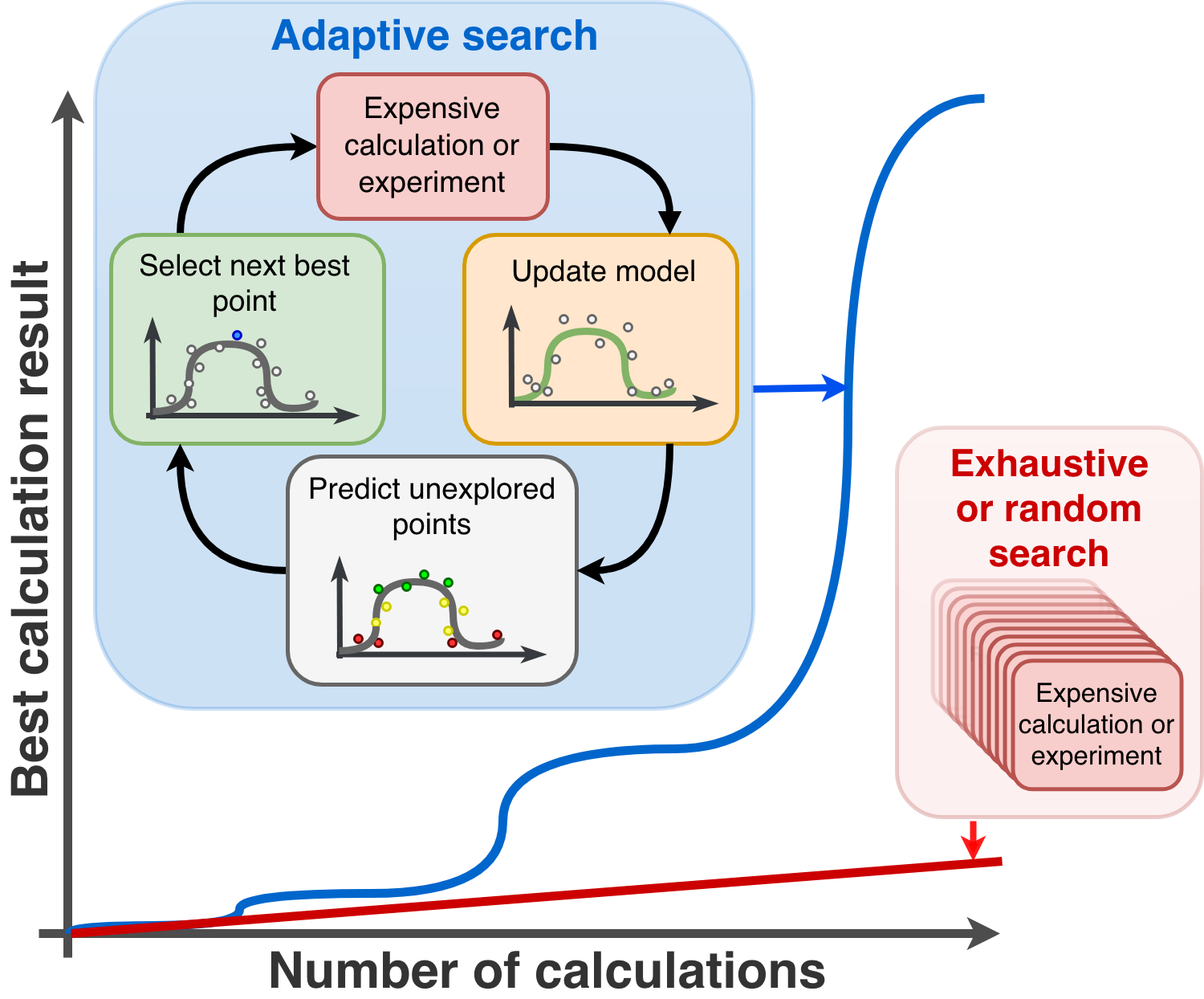
There are many packages for adaptive optimization, including skopt, optunity, and pySOT. The major aim of rocketsled is to focus on cases where:
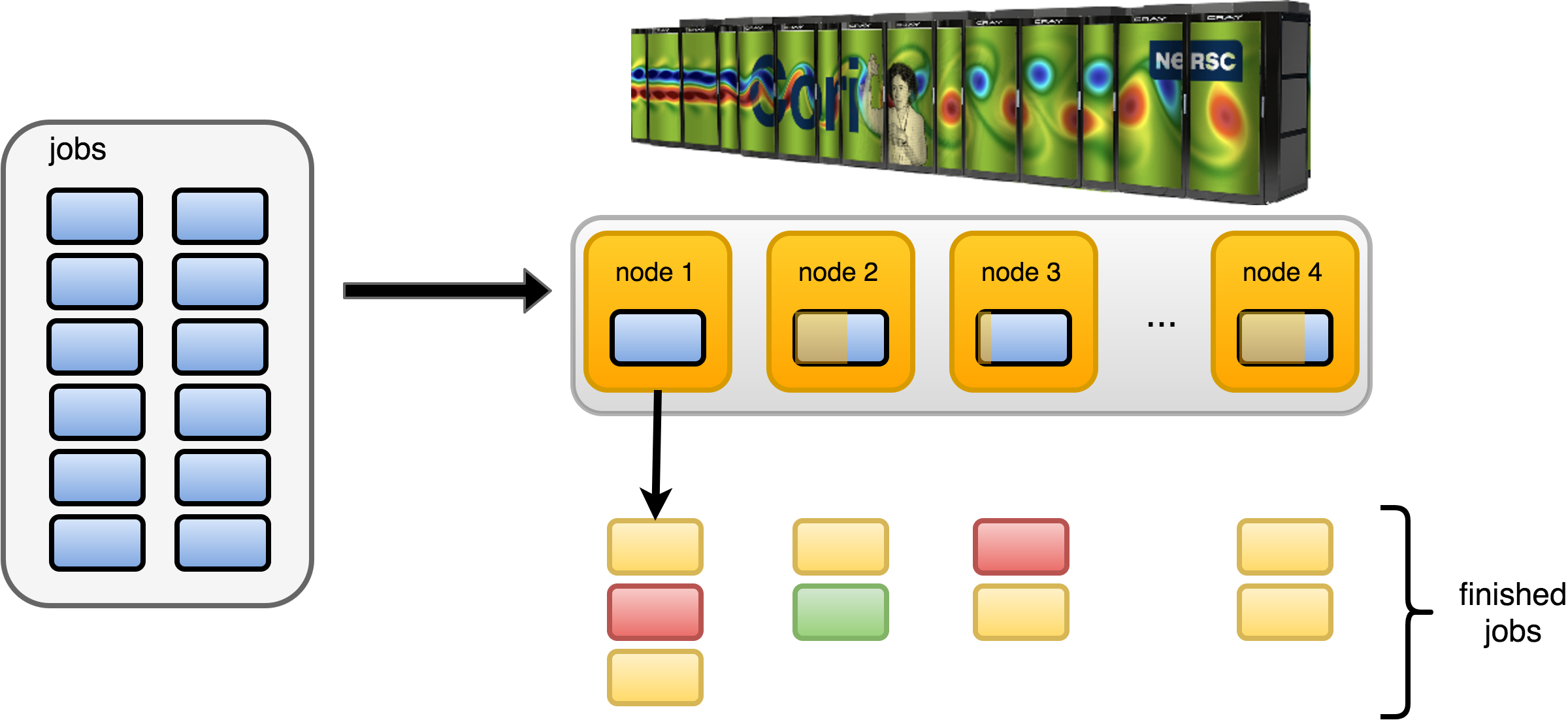
function evaluations are expensive enough that they cannot be run locally, and may instead need to be executed on supercomputing centers (e.g., through a queueing system) or external server
having a database of provenance for jobs is helpful (e.g., to help re-run error cases)
one needs to run the optimization over long time scales (days, weeks, months, or even years) with persistence.
For example, the function to optimize might be a complex physics simulation that takes days to run on a parallel supercomputer. Rocketsled helps users run such difficult optimization cases by leveraging the workflow capabilities of the underlying FireWorks software, which has been used to execute hundreds of millions of CPU-hours of simulations across millions of workflows on many different systems. The optimization algorithm itself can be set by the user or quickly selected from one of the built-in sklearn optimizers.
Is rocketsled for me?¶
Is your computational problem:
1. Expensive and/or complex (require HPC and workflow tools)?¶

2. Run in high-throughput (many similar, parallel or serial workflows)?¶
3. Limited by problem size or allocation?¶
Want to get the most “bang for your buck” with optimization?¶
If you answered yes to these three questions, keep reading!
rocketsled is an optimization framework which can automatically improve the results of your complex, high-throughput tasks using previous results. It is designed to be as extensible as possible across many computer architectures, optimization schemes, and problem specifications.
What does rocketsled do?¶
rocketsled functions as a black box optimizer for a sequential optimization loop; it solves problems of the form:
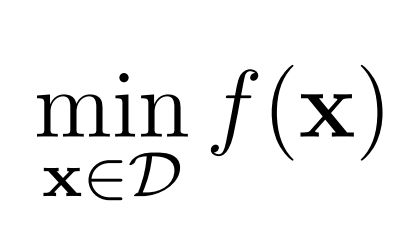
rocketsled requires no internal knowledge of f(x) for optimization. rocketsled is designed for problems where each evaluation of f(x) is highly complex, is computationally expensive, requires workflow software, or is all of the above. rocketsled is intended to be “plug-and-play”: simply plug-in an objective function or workflow f(x) and search domain D, and rocketsled automatically creates an optimization loop in FireWorks which can be easily (and dynamically) managed across arbitray computing resources.
Features of rocketsled¶
Easy python configuration tool
Persistent storage and optimization tracking
- Automatic workflow submission and management with FireWorks
Parallel execution of objective functions on HPC resources
Works with many queue systems
Several optimization execution schemes
- Ability to handle complex search spaces, including:
discrete (categorical, integer) dimensions
continuous dimensions
discontinuous spaces (subsets of entire spaces)
- 4 different built-in sklearn-based tunable Bayesian optimizers
single objective
multi objective
Support for nearly any custom optimizer written in Python (Bayesian or otherwise)
Facilitated feature engineering with
get_zargumentTuneable control of training and prediction performance, across many kinds of computer resources
Avoids submitting duplicate workflows, even when workflows run with massive parallelism
Customization of optimization scheme (sequential, batch, etc.)
Ability to run optimizations 100% in parallel
Automatic encoding for categorical optimization
and more… (see comprehensive guide)
A visual explanation…¶
A typical workflow f(x) with optimization might look like this:
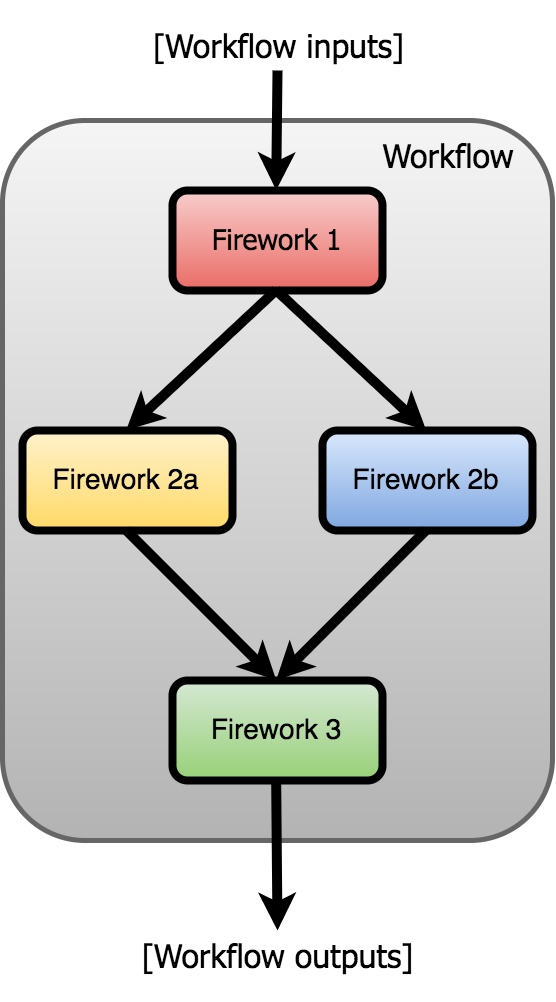
Input parameters (x) are given to the first job (Firework). This begins the workflow, and a useful output f(x) = y result is given. The workflow is repeated as desired with different input parameters, often across many compute nodes in parallel, in an attempt to compute favorable outputs.
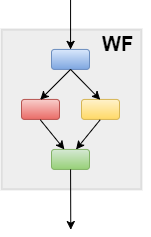
Randomly selecting the next x to run is inefficient, since we will execute many workflows, including those with unfavorable results. To increase computational efficiency, we need to intelligently choose new x with an optimization loop.
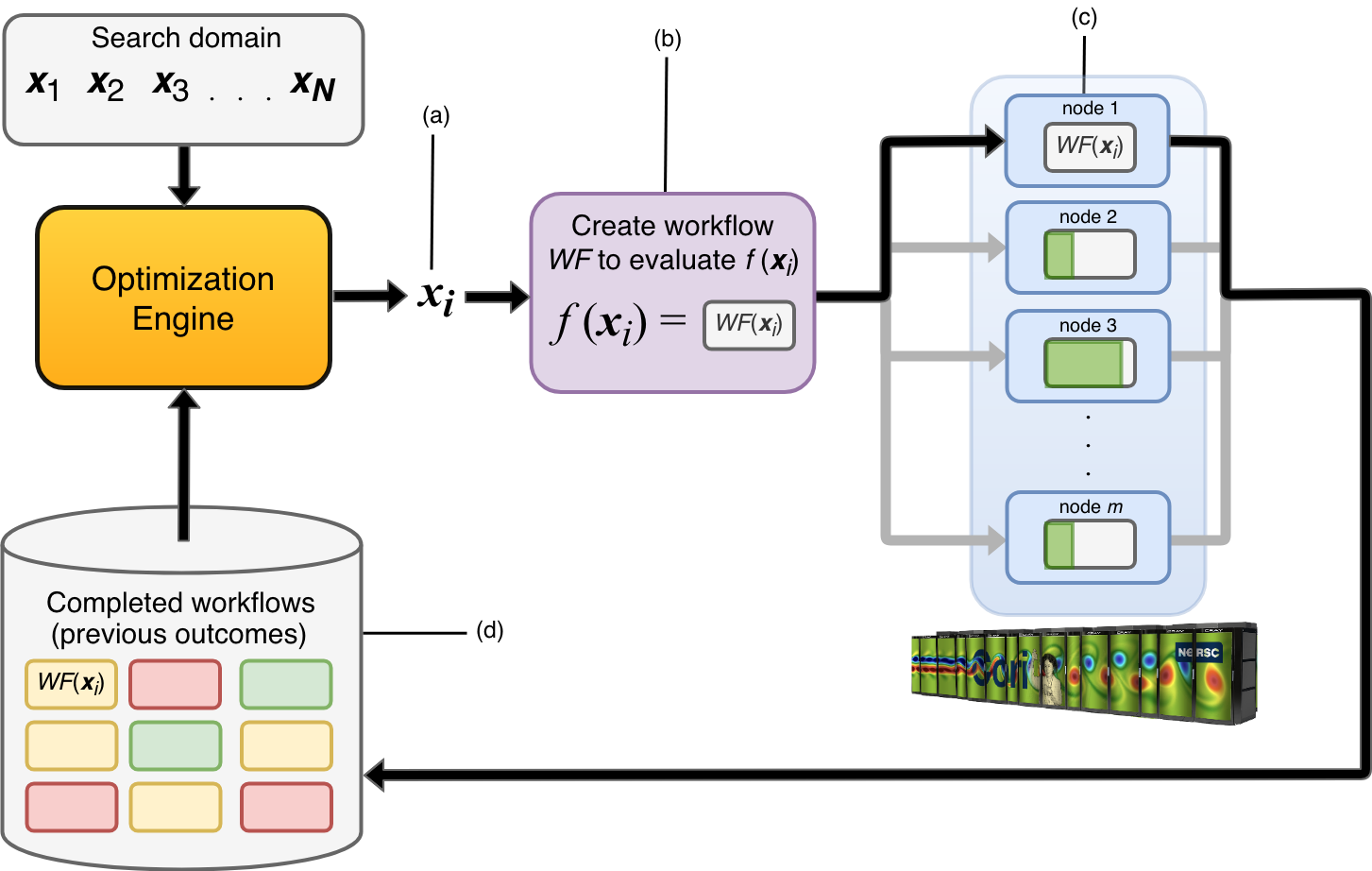
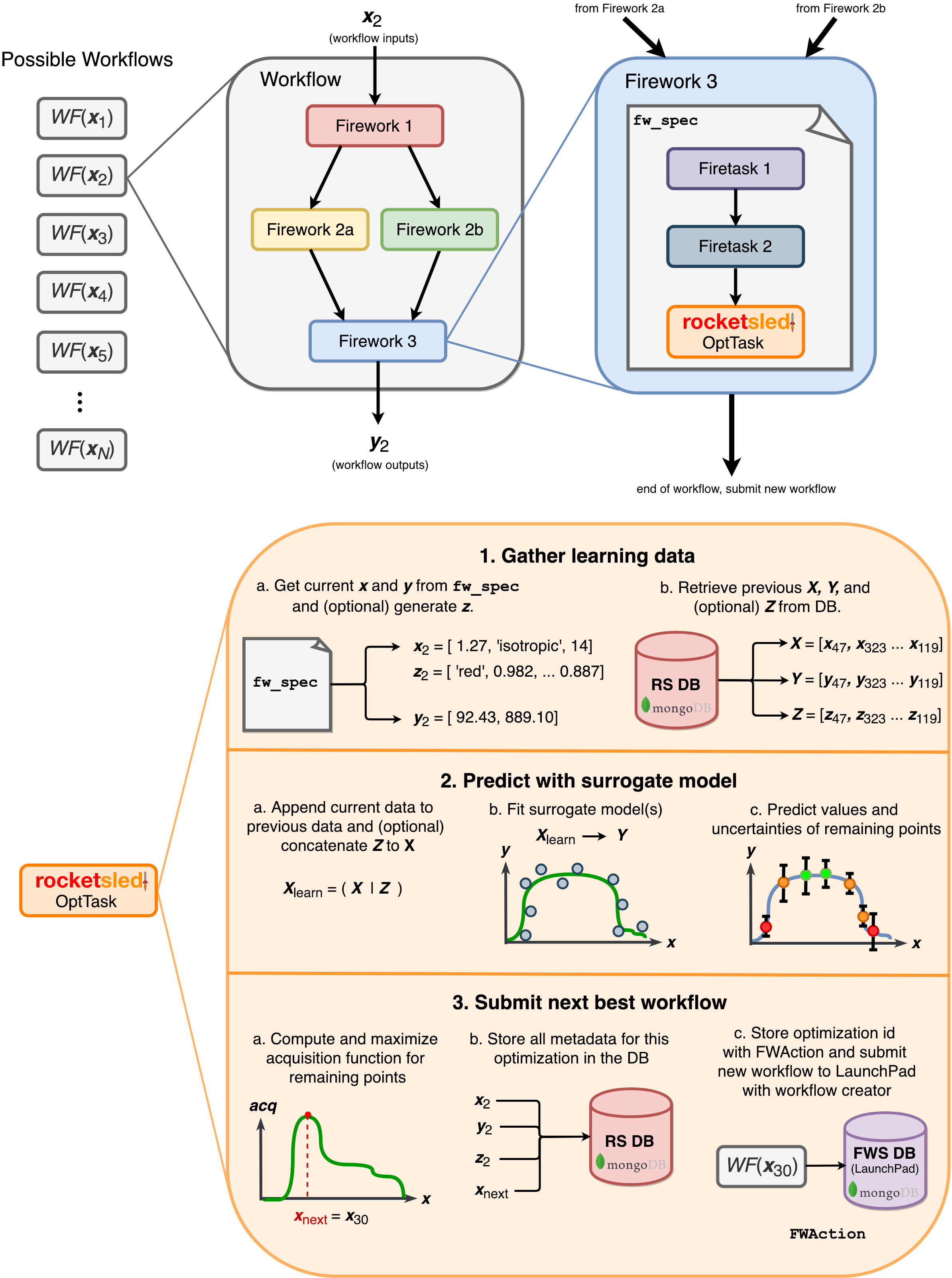
This is where rocketsled comes in handy. rocketsled is a sub-job (FireTask) which can go in any Firework in the workflow, and uses an sklearn-based Bayesian strategy to predict the best input parameters for the next iteration, store them in a MongoDB database, and automatically submit a new workflow to compute the next output.
Example use cases¶
rocketsled has many example use cases for adaptive computational problems.
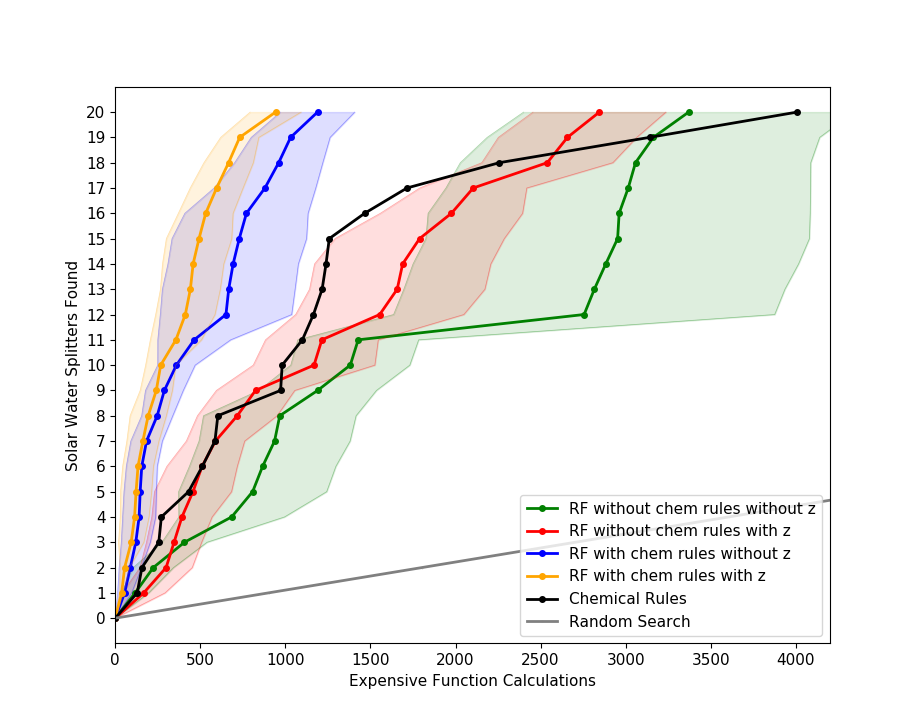
Searching 19,000 possible candidates for 20 new energy materials using expensive first-principles physics calculations: rocketsled enabled increased efficiency (wrt. random and empirical rules) in searching a large space of input parameters (materials) for renewable energy water splitting perovskites using Density Functional Theory calculations.
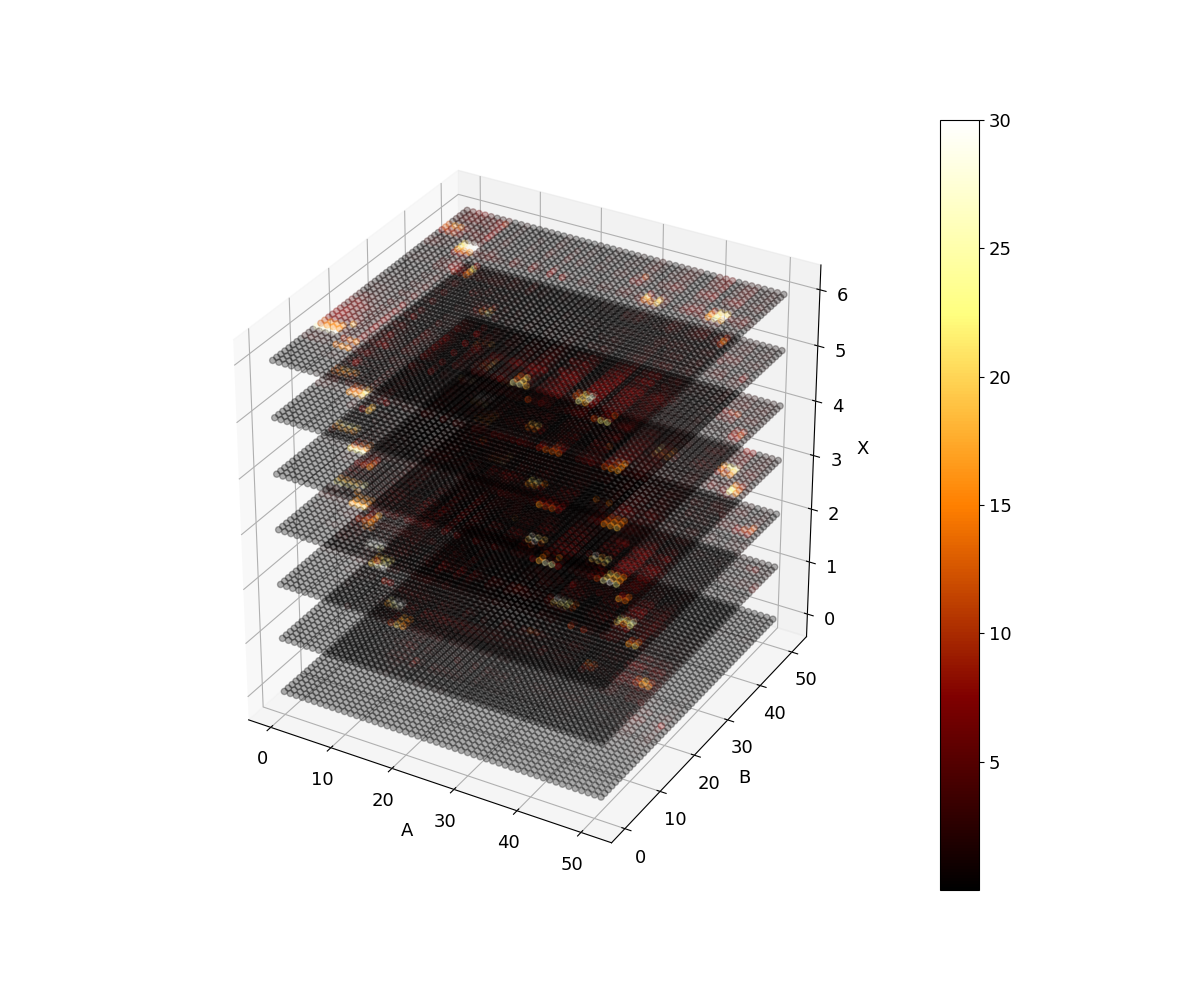
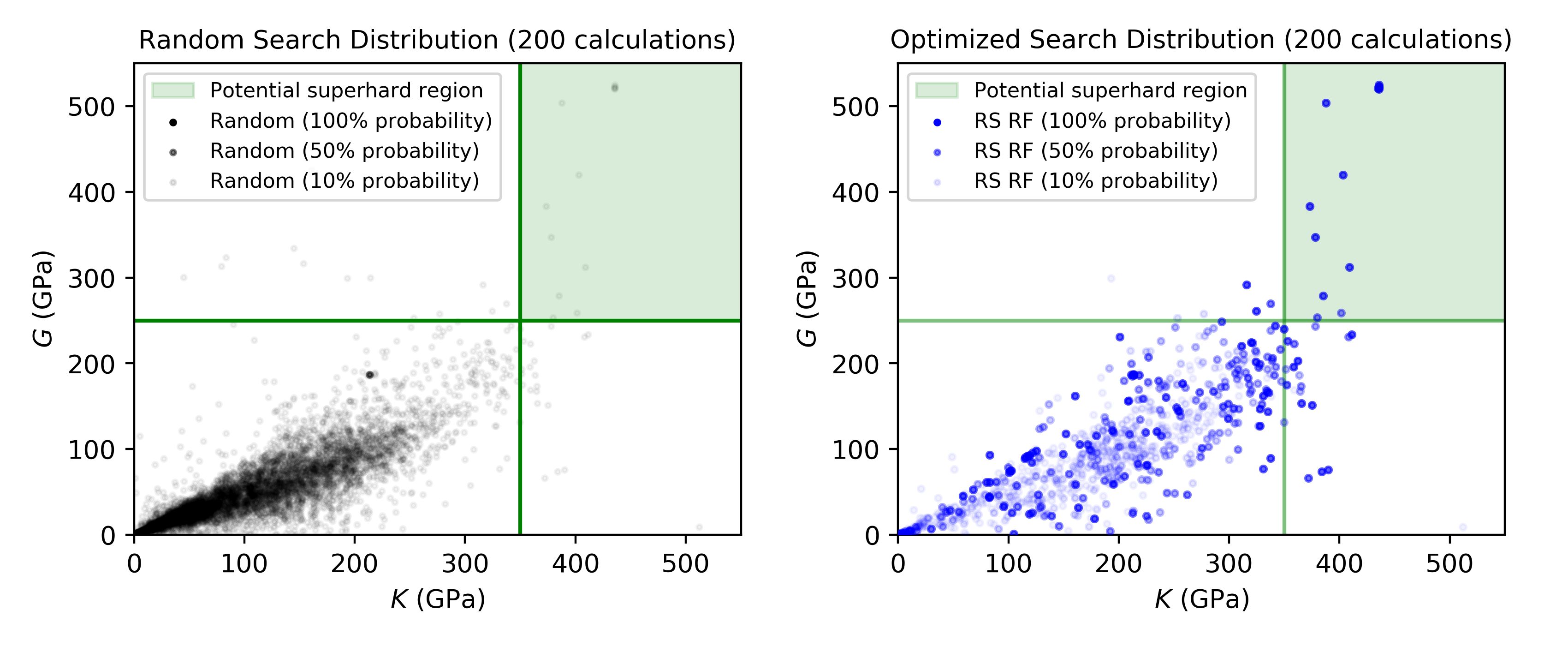
Searching 7,400 possible candidates for 8 potentially superhard materials using expensive first-principles physics calculations: rocketsled can enable faster discovery of superhard materials in searching a diverse space of materials crystal structures from the Materials Project.
(Forthcoming) Selecting the best machine learning model for large-scale data mining: rocketsled can be used for selecting the best machine learning models (and their hyperparameters) in cases where each training + cross-validation can be a computationally expensive task.
Installation¶
Requirements¶
Python 2 or 3
NumPy
SciPy
Scikit-learn
FireWorks
MongoDB
Install¶
Pip install:
$ pip install rocketsled
Or install in dev-mode:
$ # Download the repository and install
$ git clone https://github.com/hackingmaterials/rocketsled.git
$ cd rocketsled
$ pip install -e . -r requirements.txt
Run tests locally¶
$ # Rocketsled does *not* require mongo admin privileges to run, but to run
$ # tests repeatedly (i.e., for debugging), it can be helpful to first
$ # run the tests with the mongod daemon running as admin
$ mongod
$ python setup.py test
Tip: To run tests using a different mongodb (e.g., a remote fireworks launchpad), edit /rocketsled/tests/tests_launchpad.yaml!
Get Started¶
Tutorial¶
In the quickstart, we show how to use rocketsled’s MissonControl to get
up and running quickly, starting only with an objective function written in Python.
Time to complete: 30 min
A Comprehensive Guide to rocketsled¶
Find a comprehensive guide to using rocketsled at the link below. The guide
exhaustively documents the possible arguments to MissionControl and provides at least
one example of each. If working through the tutorial did not answer your
question, you’ll most likely find your answer here.
Examples¶
If neither the comprehensive guide or tutorials answered your question, working through the examples may help.
Find the examples in the source code directory under “examples”.
Contributions and Support¶
Want to see something added or changed? Here’s a few ways you can!
Help us improve the documentation. Tell us where you got ‘stuck’ and improve the install process for everyone.
Let us know about areas of the code that are difficult to understand or use.
Contribute code! Fork our Github repo and make a pull request.
Submit all questions and contact to the Online Help Forum
A comprehensive guide to contributions can be found here.
Citing rocketsled¶
Please encourage further development of rocketsled by citing the following papers:
@article{Dunn_2019,
doi = {10.1088/2515-7639/ab0c3d},
url = {https://doi.org/10.1088%2F2515-7639%2Fab0c3d},
year = 2019,
month = {apr},
publisher = {{IOP} Publishing},
volume = {2},
number = {3},
pages = {034002},
author = {Alexander Dunn and Julien Brenneck and Anubhav Jain},
title = {Rocketsled: a software library for optimizing high-throughput computational searches},
journal = {Journal of Physics: Materials},
}
@article{doi:10.1002/cpe.3505,
author = {Jain, Anubhav and Ong, Shyue Ping and Chen, Wei and Medasani, Bharat and Qu, Xiaohui and Kocher, Michael and Brafman, Miriam and Petretto, Guido and Rignanese, Gian-Marco and Hautier, Geoffroy and Gunter, Daniel and Persson, Kristin A.},
title = {FireWorks: a dynamic workflow system designed for high-throughput applications},
journal = {Concurrency and Computation: Practice and Experience},
volume = {27},
number = {17},
pages = {5037-5059},
keywords = {scientific workflows, high-throughput computing, fault-tolerant computing},
doi = {10.1002/cpe.3505},
url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/cpe.3505},
eprint = {https://onlinelibrary.wiley.com/doi/pdf/10.1002/cpe.3505},
abstract = {Summary This paper introduces FireWorks, a workflow software for running high-throughput calculation workflows at supercomputing centers. FireWorks has been used to complete over 50 million CPU-hours worth of computational chemistry and materials science calculations at the National Energy Research Supercomputing Center. It has been designed to serve the demanding high-throughput computing needs of these applications, with extensive support for (i) concurrent execution through job packing, (ii) failure detection and correction, (iii) provenance and reporting for long-running projects, (iv) automated duplicate detection, and (v) dynamic workflows (i.e., modifying the workflow graph during runtime). We have found that these features are highly relevant to enabling modern data-driven and high-throughput science applications, and we discuss our implementation strategy that rests on Python and NoSQL databases (MongoDB). Finally, we present performance data and limitations of our approach along with planned future work. Copyright © 2015 John Wiley \& Sons, Ltd.},,
year = {2015}
}