Comprehensive Guide¶
Outside of the tutorial, all of rocketsled’s configuration (which OptTask reads) can be done through the MissionControl class. The following documentation details all the possible arguments to MissionControl(…) and MissionControl.configure(…), which controls the execution and optimization parameters OptTask uses.
Arguments to MissionControl.__init__¶
Database Setup¶
To set up the database.
launchpad¶
A FireWorks launchpad object. Used in lieu of host, port, and name.
Examples
lpad=LaunchPad(host='localhost', port=27017, name='rsled')
opt_label¶
The name of the collection where optimization data will be stored. Make sure only rocketsled data is stored in this collection!
Examples
#opt_label should be a string
opt_label="my_opt_collection"
Required Arguments to MissionControl.configure¶
The required arguments are wf_creator and dimensions¶
wf_creator¶
This is a function object which takes in an input vector x and returns your optimization loop workflow. The function must
Accept x
- Return a Fireworks workflow based on x (i.e., x sets some parameters in the workflow)
The workflow must contain OptTask
The Firework containing OptTask must have spec fields ‘_x’ and ‘_y’ containing your x optimization vector and y optimization vector/scalar. A vector used for y is considered a multiobjective optimization.
The workflow that is returned should have OptTask contained somewhere in it. Since OptTask is in the workflow, this is somewhat recursive.
You can also pass in full string path of the wf_creator function.
Example
wf_creator=my_wf_creator_fun_object
Alternatively, define it with a string.
Example
wf_creator='my_package.my_module.my_wf_creator'
Alternatively, you can use a function contained in a file not in registered module. While this may work, it is NOT recommended!
Example
wf_creator='/path/to/my_module.my_wf_creator'
For this to work, your file needs to be present at this path on all computing resources used for execution. Additionally, this file should be in the PYTHONPATH. Thus it is HIGHLY RECOMMENDED you place your wf_creator
somewhere in a python package (e.g., my_package.my_module.my_other_module.my_wf_creator) accessible on all the systems you plan to use rocketsled on.
See the basic tutorial or the examples folder for examples of writing wf_creator functions.
dimensions¶
A list of tuples or lists defining the constraints of the search space. 2-tuples of floats or ints are considered ranges of the form (low, high), and will search all possible entries in between. Lists of strings are considered comprehensive domains of categorical dimensions, where there is no spatial relation between entries. Lists of length 2 or larger of integers and floats are considered discontinuous dimensions. In discontinuous searches, all possible combinations of discontinuous dimension values can be searched.
Examples
# 3 integer dimensions defined by ranges. There are 125 possibilities in this search space.
dimensions=[(1, 5), (1, 5), (1, 5)]
# 3 float dimensions
dimensions=[(1.0, 5.0), (1.0, 5.0), (1.0, 5.0)]
# 3 categorical dimensions
dimensions=[["red", "green"], ["tiger", "bear"], ["M", "T", "W", "R", "F"]]
# A combination of categorial and ranged number dimensions
dimensions=[(1.0, 12.0), (5, 10), ["badger", "antelope"]]
# Discontinuous dimensions
dimensions=[[1.332, 4.565, 19.030], [221.222, 221.0283, 221.099]]
Note: If your search space cannot be described by dimensions alone (i.e., it is a set of discontinuous points which can’t be described by ranges or combinatorically, as above, see the ‘space_file’ argument
Optional Arguments to MissionControl.configure¶
Predictors¶
Predictors power rocketsled’s optimization. Choose one of the built-in predictors or use a custom function.
predictor¶
A string naming a function which, given a list of explored points and unexplored points, returns an optimized guess.
Builtins
Included sklearn-based predictors are:
‘RandomForestRegressor’,
‘ExtraTreesRegressor’,
‘GradientBoostingRegressor’,
‘GaussianProcessRegressor’,
Defaults to ‘RandomForestRegressor’
To use a random guess, choose ‘random’.
Custom
A function object for your predictor, or the string for the fully qualified name of your predictor function. The predictor function itself should have the form:
def my_predictor(XZ_explored, Y, x_dims, XZ_unexplored)
"""
Returns a prediction for the next best guess. The returned guess will
be used to construct a new workflow with the workflow creator function.
The argument names need not be the same shown here, although their
position must remain the same.
Args:
XZ_explored ([list]): A list of lists; 2D array of samples (rows)
by features (columns) of points already evaluated in the search
space. This is training data.
Y (list): A vector of samples; this is the training output.
x_dims (list): The dimensions of the search space
XZ_unexplored([list[): A list of lists; 2D array of samples (rows)
by features (columns) of points to be predicted. This is the 'test'
or prediction dataset.
Returns:
x (list): A vector representing the set of parameters for the next best
guess
"""
# Here is an example custom predictor
X_train = XZ_explored
y_train = Y
X_test = XZ_unexplored
SVR().fit(X_train, y_train)
possible_values = SVR.predict(X_test)
best_x = custom_find_best_val_function(X_test, possible_values)
return best_x
You can also add additional predictor positional arguments and keyword arguments
with the predictor_args and predictor_kwargs arguments (see below).
Example
# Example builtin predictor:
predictor='RandomForestRegressor'
# Example custom predictor:
predictor = my_predictor_function_object
# Or equivalently as a string
predictor='my_package.my_module.my_predictor'
predictor_args¶
Additional positional arguments to the chosen predictor, whether it be builtin or custom, as a list.
For builtin predictors, arguments are passed to the sklearn BaseEstimator. For custom predictors, arguments are passed directly to the predictor function after all default arguments are passed (see ‘predictors’ argument above for the default arguments).
Example
predictor_args=[5, 7.9, "some_positional_hyperparam_value"]
predictor_kwargs¶
Additional keyword arguments to the chosen predictor, whether it be builtin or custom, as a dictionary.
For builtin predictors, arguments are passed to the sklearn BaseEstimator. For custom predictors, arguments are passed directly to the predictor function.
Example
# Example builtin predictor: The regressor you chose as predictor should accept these arguments!
predictor_args={"n_estimators": 100, "criterion": "mse"}
# Example custom predictor:
predictor={"my_kwarg1": 12, "my_kwarg2": "brown"}
For more info, see the batch.py example’s custom predictor function where batch_size is used as a custom predictor function kwarg.
Workflow creator function¶
wf_creator_args¶
Positional args to pass to the wf_creator alongside the new x vector.
Example
# positional args should be a list
wf_creator_args=["my_creator_arg", 12]
See extras.py for an example.
wf_creator_kwargs¶
Keyword arguments to pass to the wf_creator, as a dict.
Example
# kwargs to pass to the wf_creator
wf_creator_kwargs={"my_wf_creator_kwarg": 12}
See extras.py for an example.
Predictor Performance¶
Options in this section are used for
Improving optimization performance
Reducing search space
Balancing exploitaton and exploration
n_search_pts¶
The number of points to be predicted in the search space when choosing the next best point.
Choosing more points to search may increase the effectiveness of the optimization, but will require more computational power to predict. The default is 1000 points.
if the size of the domain is discrete and less than n_search_pts, all the remaining points in the domain will be predicted.
Example
# n_searchpts should be an int
n_search_pts=10000
n_train_pts¶
The number of already explored points to be chosen for training, sampled at random without replacement from the explored space. Default is None, meaning all available points will be used for training. Reduce the number of points to decrease training times.
Example
# n_searchpts should be an int
n_train_pts=10000
space_file¶
The fully specified path of a pickle file containing a list of all possible searchable x vectors (tuples).
Use this argument if you have a space which cannot be defined sufficiently by dimensions.
Note: The dimensions argument is still needed. Make sure dimensions encapsulates the full range of points in the space specified here
Example
# The pickle file should contain a list of tuples
space_file='/Users/myuser/myfolder/myspace.p'
acq¶
The acquisition function to use for Bayesian optimization with builtin predictors. Using an acquisition function leverages what we know about the objective function and statistical estimates to balance exploration and exploitation. Using this option will increase the effectiveness of optimization, but more optimization overhead will be used (see below for tips).
Choose from the following options:
Single objective:
None: The highest predicted point is picked. Fully exploitive.
‘ei’: Expected improvement (Recommended)
‘pi’: Probability of Improvment
‘lcb’: Lower confidence bound
Multi objective: * None: The points which are predicted to be Pareo-optimal are picked with equal probability. Fully exploitative. * ‘maximin’: An acquisition function similar to Expected Improvement which combines the minimum gain in the maximum objective dimension over the entire Pareto-fronteir with the probability of improvmeent.
Example
# The acquisition function should be a string or None
acq='ei'
Tip: For all builtin predictors besides Gaussian processes, bootstrapping is required (for statistical estimates), which can be computationally intensive. If you’re using acquisition functions and need quick predictions, we recommend GaussianProcessRegeressor as a predictor.
n_bootstraps¶
The number of bootstrap samples and retrains/re-predictions used for bootstrapping when estimating uncertainty. When calculating acquisition values, for all builtin predictors besides Gaussian processes, bootstrapping is required (for statistical estimates).
Increasing n_bootstraps will linearly increase training time and prediction times, but will increase prediction performance if using an acquisition function.
The default n_boots is 500, although higher is better!
All bootstrapped training and acquisition is performed in parallel, if possible.
Example
# The number of bootstraps should be an integer.
n_bootstraps=1000
onehot_categorical¶
Automatic One-Hot encoding of categorical input for custom predictors.
If using a custom predictor, explored and unexplored spaces will be passed to
the predictor as strings, if categorical dimensions exist. With onehot_categorical=True,
the custom predictor will receive only numerical input (although it may be a combination of
ints and floats). Default is False, meaning no categorical encoding.
Example
onehot_categorical=True
duplicate_check¶
Ensure custom predictors do not submit duplicates (even in parallel).
Builtin predictors do not suggest duplicates, even when many workflows are running in parallel, since rocketsled
locks the optimization db sequentially. However, custom predictors may suggest duplicates. Enabling duplicate
checking will prevent duplicate workflows from being run (the meaning of “duplicate” can be refined with tolerances)
when using custom predictors. Suggested duplicates are discarded and random guesses from the remaining unexplored space are used instead.
Default is no duplicate check; if a duplicate is suggested, an error is raised.
Example
# duplicate_check is a bool
duplicate_check=True
tolerances¶
The numerical tolerance of each feature when duplicate checking, as a list per dimension. For categorical features, put ‘None’
Example
# if our dimensions are [(1, 100), ['red', 'blue'], (2.0, 20.0)]
# and we want the first param to be a duplicate only if it is an exact match
# and the third param to be a duplicate if it is within 1e-6, then
tolerances=[0, None, 1e-6]
maximize¶
If true, makes optimization tend toward maximum values instead of minimum ones.
By default, false.
For multiobjective optimization, the maximization rule applies to all objective metrics.
Example
maximize=True
z-vector¶
Using features derived from x can provide more information to predictors. These extra features, which do not uniquely define the workflow but are nonetheless useful, are called “z”.
get_z¶
The function object or fully defined string representing a function that, when given a vector x, return any number of derived features. Derived features can be any of the types rocketsled can handle (float, int, categorical).
The features defined in z are not used to run the workflow, but are used for learning. If z features are enabled, ONLY z features will be used for learning (x vectors essentially become tags or identifiers only). To use x features and z features, simply add x features to the returned z vector.
Dimensions are not necessary when using get_z.
Example
# the function object itself
get_z=my_get_z_function_object
# Equivalently, as a string
get_z='my_package.my_module.my_fun'
# Alternatively...
get_z='/path/to/folder/containing/my_package.my_module.my_fun'
Here’s an example of the form get_z should take as a function. It takes in a vector x and returns a vector z. The z vector can be any length.
# my_module.py
# Features are derived from the x vector, but do not uniquely define it.
def get_z(x):
return [x, x[1]*2, some_featurization_function(x), x[4] ** 3.0]
get_z_args¶
Positional arguments to pass to get_z. These are passed to get_z after x, the necessary default argument.
Example
# get_z_args should be a list of positional args
get_z_args=["somearg", 14]
get_z_kwargs¶
Keyword args to pass to get_z.
Example
# get_z_kwargs should be a dict of kwargs
get_z_kwargs={'somekwarg': 12}
z_file¶
The filename (pickle file) which should be used to store persistent z calculations. Specify this argument if calculating z for many (n_search_pts) is not trivial and will cost time in computing. With this argument specified, each z will only be calculated once. Defaults to None, meaning that all unexplored z are re-calculated each iteration.
Example
# persistent_z defines the file where OptTask will write all z guesses.
z_file = '/path/to/persistent_z_guesses.p'
Parallelism¶
batch_size¶
Rocketsled is capable of batch optimization, meaning that N workflows are run, then a single optimization is run, and then another N workflows are submitted using the N best guesses from the optimization.
Enabling batch optimization is useful if you do not want to wait for many sequential optimizations, or if little information is gained from each workflow evaluation but you are running many cheap workflows.
The batch_size parameter determines the batch size; default 1.
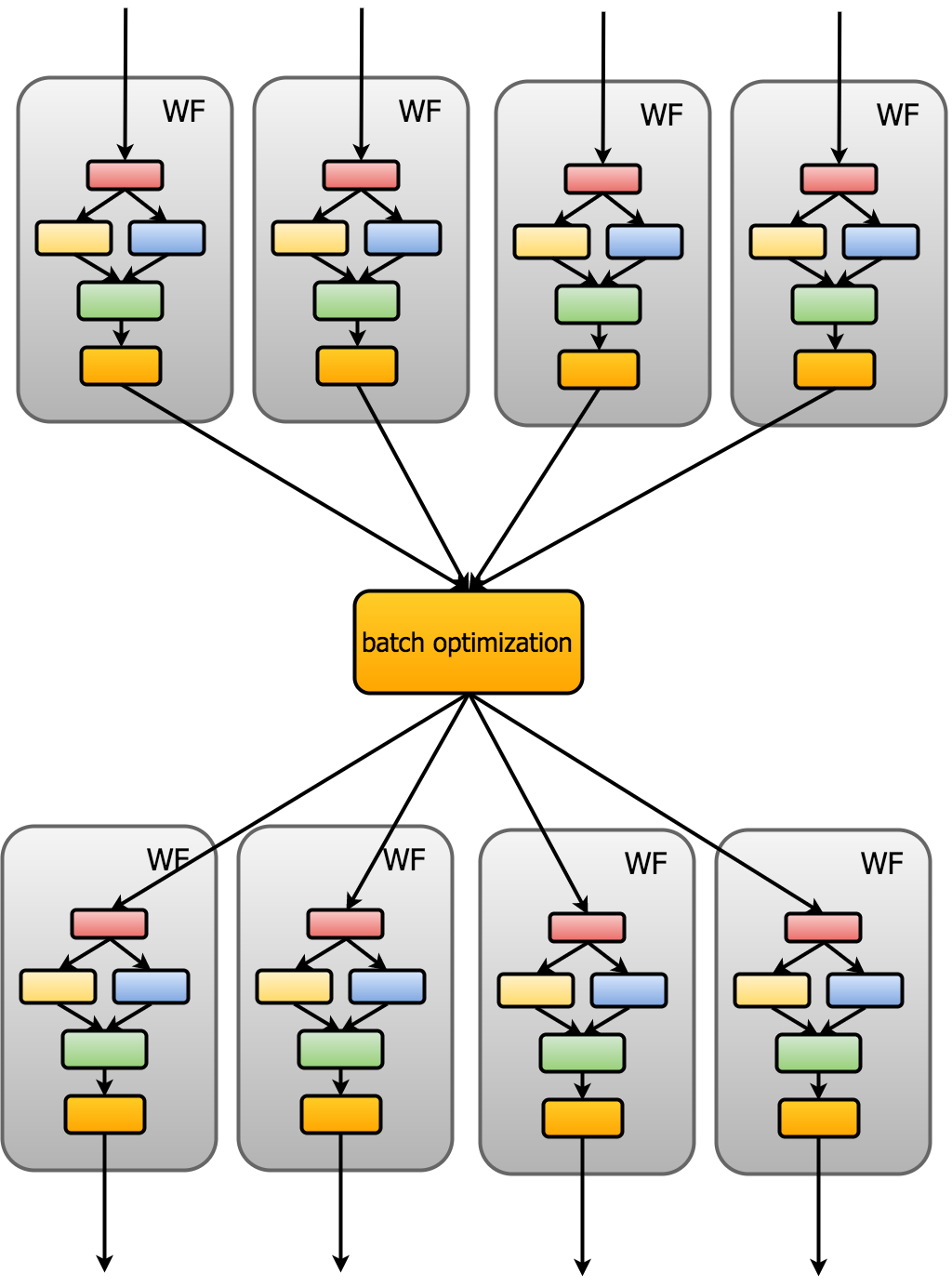
Example
# optimize every 20th job, then submit another 20 workflows to the launchpad
batch_size=20
Note if using a custom predictor, your custom predictor should return the same number of guesses as the batch_size.
See batch.py example for a demonstration.
Note: Enabling large batch sizes may cause synchronicity issues. For example, rocketsled waits for all batch calcs to finish before running another batch. If one calc fails, the batch optimization will fail.
enforce_sequential¶
Warning! Experimental feature!
Gives the ability to run optimizations 100% in parallel. This option disables all duplicate checking ability - even with built-in optimizers, duplicates may be selected and run.
When True, the entire workflow besides optimization can be run in parallel. When False, the entire workflow including optimization can be run in parallel.
Example
# We don't care about duplicate checking, but want to run everything in parallel
enforce_sequential=False # May cause bugs!
timeout¶
The number of seconds to wait before resetting the lock on the db.
Rocketsled can leave the db locked for long periods of time (causing all other optimizations in parallel to stall) if a process exits unexpectedly, loses connection with the optimization collection, or takes an extended (5+ min) time to train and predict. The db can be temporarily released from lock, but if there is a systematic error, rocketsled will not be able to make predictions while the db is perpetually locked and reset.
Choosing a sensible timeout will prevent rocketsled from wasting throughput when making predictions.
If your predictions are unexpectedly exiting or rocketsled is consistently voiding predictions (not submitting new workflows), your problem is most likely with the timeout setting.
Example
# If a prediction is expected to take no more than 5 min, we want to set the timeout accordingly.
timeout=300 #seconds